
Sanatçı Refik Anadol, ANAMED direktörü Chris Roosevelt, ANAMED’in “Bir Kazı Hikâyesi: Çatalhöyük” sergisi küratörü Duygu Tarkan ve koordinatörü Şeyda Çetin, Refik Anadol’un sergi kapsamında gerçekleştirdiği medya enstalasyonu üzerine söyleşiyor.
RA: Şimdi şöyle başladı hikâye, ilk başta sorduklarımız şuydu: “Makine öğrenmesini bu muhteşem arşive nasıl uygulamalı? İnsan bakışından farklı bir sonuca ulaşabilmek için derin öğrenme algoritmaları nasıl uygulanmalı? Bu zengin veri tabanından nasıl bir değer üretilebilir?” Bütün bu sorular veri tabanını geliştiren ekip tarafından da çok beğenildi, heyecanla karşılandı. Ama pratik olarak bazı zorluklar vardı. Veri tabanını geliştiren Dominik Lucas’la süreci görüştük. Tabii bir diğer taraftan şu an stüdyomuzdaki veri bilimci, sanal gerçeklik mühendisi ve üretimsel tasarımcılar olmakla birlikte benimle beraber 5 kişilik bir ekip olarak proje üzerinde çalıştık. Veri madenciliği kısmı çok zaman aldı çünkü arşiv, her yeni gelen araştırmacının bir daha yorumladığı bir şeye dönüşmüş. 900 küsur tane CSV (Virgülle Ayrılmış Değerler) dosyası var yani bu demek ki 900 küsur kere bir şeyler yorumlanmış bilgisayar için. Ve her birinin de kolon yapısı, her kişinin kendi çalışma sistemine göre yorumlanmış. Yani her ekibin kendi yönlendirmeleri olmuş veriye.
DT: Aslında ayrı ayrı oluşturulan derken, o veri tabanından çektiğimiz “queries” yani “sorgulamalar”dan bahsediyorsun değil mi?
RA: Evet, evet. Yani bir tane big picture verisi yok aslında. Sonuçta bir tıkla bir anda bütün arşivi bir dosyaya aktarmak gibi bir fikir çalışmadı. Güzel bir problem bu, çünkü bilgisayar bilimi açısından baktığımız zaman veri darmadağınık, bu iyi bir sebep. Herkes kendi yorumunu eklemiş bu da iyi bir sebep. Sonra dedik ki peki makine bunu nasıl okuyabilir. Bunu okuyabilmesi için ne yapmamız gerekiyor? Büyük çözünürlükte fotoğraflara baktığımız zaman bütün imaj arşivi çok yeterli, çok kuvvetli, zaten yeteri kadar bilgi var, her şey güzel kaydedilmiş.
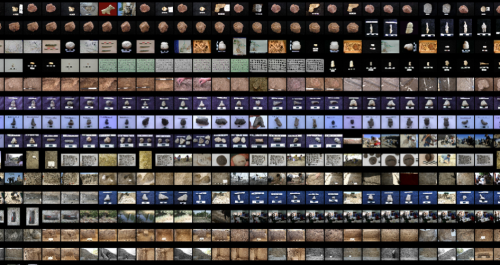
Kontakt Baskı (contact sheet)” Imaj Arşivi Dizilimi, Refik Anadol, Çatalhöyük Araştırma Projesi Arşivi, 2017
Fon renkleri farklı olsa da, kimi gelen beyaz kullanmış kimi siyah. Duruma göre herkes o an bir şey üretmiş yani ama aslında “bilgisayarlı görüntüsü” için gerekli bilgi var. Sonra şöyle zorlu bir aşama daha oldu; peki bu kadar fotoğraf, mesela 2006 – 2016 arasındaki çözünürlük farkı da uçurum…Çok küçük, 640’a 480 piksellik fotoğraflar da var, yeni çekilenler mesela 7000’e çıkmış. Yani aradaki fark uçurum. Sonra bir algoritma yazmamız gerekti, bütün fotoğrafları alıp imgeleri tek tek onarıp sabitledik.

Refik Anadol, Çatalhöyük Araştırma Projesi Arşivi, 2017
Bu aslında bir “kontakt baskı (contact sheet)” sahnesi. Burada da bunu yaparken ilk çekilen sol üstteki fotoğrafla son çekilen sağ alttaki fotoğrafa kadar sanki kazı evinde çalışan grupların çekim anlayışına göre en soldan en sağa kronolojik şekilde dizdik. Çok enteresan gözüktü aslında posterde. Çünkü aslında çalışmayı da çizgisel düzlemde gösterdi. Aslında burada kompleks bir türde makine zekâsı uygulanmadı. Yani tarihsel olarak dizildi. Bu mesela tek başına 3 gün süren bir süreçti. Bütün arşivi tek tek imajı bulup küçültüp bir yere koyup, tekrar küçültüp bir yere koyup sonra verilen enstalasyon ebatlarına göre en sol üstten en sağ alta kadar piksel piksel tekrar inceleyip düzenleme yapıldı. Bu başlı başına bayağı zaman alan bir süreçti. Sonra aynı veriyi işleme sürecinde (processing) java ile acaba bir dosyaya indirebilir miyiz diye sorduk. Meta veriye ulaşıp bir şekilde suni olarak, sentetik bir meta veri yaratıp imgelere bir daha bakabilir miyiz diye düşündük.

CSV Aracıları: Aracı-Metaveri Hesaplaması, Refik Anadol, Çatalhöyük Araştırma Projesi Arşivi, 2017
ŞÇ: O halde burada gördüklerimiz yine imgeler; yani arşivindeki fotoğraflar arasındaki ilişkiyi görmeye devam ediyoruz bu sahnede de.
RA: Evet. Her bir küp bir veri noktası.
CR: Veri noktası derken neyi kastediyoruz? Tek bir fotoğraf mı?
RA: Bir fotoğraf. Çünkü imgeler dışında veriyi mutlak olarak çözebilmek metin boyutunda mümkün ama o da çok kısıtlı kaldı. Görsel veri, bizim ve makinanın görebildiği bir şey gibi düşündüğümüz zaman daha rahat bağlama oturtulabildi. Bu sahne de aslında şunu gösteriyor: acaba böyle bir evren yaratabilir miyiz?
CR: Gerçekten. Bu bana evrendeki bir solucan deliğini anımsatıyor. Yani, bu koridor uzunlamasına bakıldığında koridor mi? Eğer tünel kronolojik ise, onu yuvarlak kılan ne? Bu tasarım kaynaklı mı?
RA: Evet. Üstten baktığınızda aslında tam da onu görüyorsunuz. Bu sanatsal bir unsur. Ancak bence bu biraz da işe daha içine alan bir etki sağlıyor. Bundan çok daha büyük yapılabilirdi. Ancak sonra çok fazla üst üste çakışma olduğunu fark ettim. Kelimenin tam anlamıyla algılanabilirlik açısından, her bir noktanın bireysel deneyimi algılanamıyordu..
Bazı durumlarda her bir küpün bir veri noktasına sahip olması ve bunların her birine ilişkin arşivin onlar hakkında bir şeyler söylediği bir CSV dosyası olması amacıyla bir CSV’nin her bir noktasını tek tek ele aldığımız zamanlar oldu. Ve bu kodu sadece bu yapısal mekânı yaratmak için yazdık.

Giriş Sahnesi: Alanın Ağ Görüntüsü, Refik Anadol, Çatalhöyük Araştırma Projesi Arşivi, 2017
RA: Burada ise fotogrametri denenmiş drone ile. Sonra bu “ağ örüntüsü”ne çevrildi. Çok güzel bir çalışma, bayağı bir zaman harcandı buna. Dedim ki acaba böyle bir mekâna makine zekâsı uyguluyorsak klişe bir şekilde, yani, 2 boyutlu ya da 3 boyutlu bir görsellikle mekânı makine perspektifiyle nasıl görürdük? Böyle bir sahneyi görürdü gibi düşündüm.
ŞÇ: Burada, arazinin üzerindeki ağ topoğrafyadaki farkları mı gösteriyor?
RA: Kot farkını gösteriyor. 3 boyutlu bir tarama yapılmış fotoğraftan fotogrametri ile. Çok başarılı bir şey denenmiş. Zaten renk skalası alınmış, çok düşük çözünürlüklü bir topoğrafya görüntüsü tabii ki. Ama estetik olarak bence çok güçlü.
ŞÇ: Bu zaten hani o ağlarla birlikte, topoğrafyayı gösteren o noktasal görünümle, adeta bir Paul Signac tablosu. Karşımda ilk gördüğümde dijital bir imgenin günün sonunda gerçekten bir tablo estetiğine büründüğünü düşündüm.
RA: Çok güzel. Aynı ilhamı verdi yani görür görmez. Çok zaman aldı bu arada. Böyle rahat bir çalışma dosyası değil yüksek çözünürlüklü bir imaj kitlesi var üzerinde. Kamerayı rahatça üzerinden gezdirip basit bir sinematografik bir geliştirme bile 2 günlük bir süreçti. Doğru şekilde dokuyu alıp kamerayı koyup topoğrafyayı 3 boyutlu bir daha okutmanın beklenmedik bir sorumluluğu varmış arkasında. Kolay gözüküyordu ama bu da bayağı keyifliydi.
ŞÇ: Zaten bu görseli çıkardığını gördüğümde “İnanmıyorum, arşivin içinde nasıl derin bir araştırma yapmış!” dedim. Çünkü sana kılavuzu olmayan muntazam büyüklükte bir veri tabanı teslim ettik. Ve sen, kelimenin tam anlamıyla bu arşivde kendi arkeolojik kazını yapmışsın.
RA: İlk soru, bu kazı alanının tam olarak nerede olduğudur? Mekânı fiziksel olarak görebilir veya coğrafi olarak bağlantı ve bağlamı hissedebilirsiniz. Bence bu deneyime bu noktadan başlamak bir çeşit giriş bölümü niteliğinde oldu.
Bunun ardından gördüğümüz şey ise, ilginç bir şekilde, verilerin kazılarak çıkarıldığı ile aynı peyzaj, aynı topoğrafya; bu biçimi almaya başladığı için biz de “Houdini” adlı bir yazılım kullandık. Bu çok karmaşık bir 3-boyutlu prosedürsel tasarım yazılımıdır ve milyonlarca noktayı işlemenin üstesinden gelebilir. Yani bizim bu ölçekte, CSV dosyalarından gelen yaklaşık 1,1 milyon tekil noktamız var. Bazen bunlar sadece birer resimdir, ancak bir şekilde benzersiz bir bilgiyi temsil ederler.

Stanford t-SNE ArchGIS Alan Haritası, Çatalhöyük Araştırma Projesi Arşivi, Refik Anadol, 2017
RA: Burada renk önceki sahneden geliyor, ancak nihayetinde her nokta arşivdeki benzersiz bir verinin basitleştirilmesine karşılık gelmekte. Ve daha sonra, bu kamerayla, sadece peyzajın bu bağlamda uçsuz bucaksız ve devasa olduğunu ifade etmeye çalışıyordum. Burada kullandığımız algoritma “t-SNE”. Basitçe açıklamak gerekirse, bu algoritma milyonlarca veri noktası arasındaki en yakın komşuluk ilişkisini elde eder.
Şimdi bütün arşivi çok kabaca 256 – 256 piksele bölmek gerekiyor ilk başta. Her imajın kusursuz bir şekilde bir kare içinde var olması gerekiyor. Daha sonra bu imaj gömme (embedding) sayısı genelde, yani 1024 gibi bir rakam, hemen hemen büyük ölçekte imajlar arasındaki yaklaşımı gösterecek kadar büyük bir veri. Her birini defalarca uyguladığımız zaman aslında boyut 1004. Yeteri kadar büyük bir veri aslında. Elimizde çok büyük ihtimalle bir bulgu var.
CR: Ben de tam, “Bu, temel bileşen analizi (Principle Component Analyses),”diyecektim.
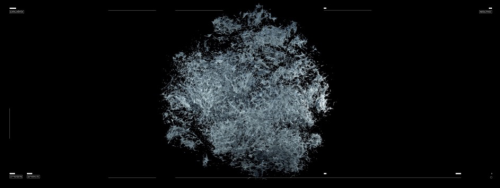
Site Lerp: Vectorization of Orthomosaic, Refik Anadol, Çatalhöyük Araştırma Projesi Arşivi, 2017
RA: Evet. Daha sonra burada gördüğümüz aslında noktalar landscape lerp denen bir algoritmayla bir anda o “t-SNE”grubuna dönüşüyor. Bu dönüşüm aslında çok enteresan bir nokta çünkü sonraki sekansta o peyzajın kendisi böyle bir forma dönüşüyor. Bu gördüğümüz de 50 çapraşıklık (perplexity) ile oluşturuldu. Çapraşıklık da o algoritmanın keskinlik(sharpness) rakamı diye söylenebilir. 5 ile 50 arasında bir rakam aralığı. Her biri 5’er 5’er artacak şekilde kullanılabiliyor. 50’nin bize en dağınık ve en kümesel bağları koparabilen bir hal getirebildiğini fark ettik. 5 çok iç içe geçiyor mesela, 20 – 25 hala arada kalıyor ama 50’de bağlantısız bulgular ortaya çıkıyor. Tek sıkıntı: çok ağır bir dosya, dolayısıyla içinde bir yakınlaştırma ve uzaklaştırma yapmak için veri işlemek 1 ay daha sürecek bir süreçti. O yüzden sanatsal olarak bir şiirsel görünümü yakalayabileceğimiz çok hızlı bir yakınlaştırma yapılabilir mi konusunu sorguladık. Mesela bu sahne 5 gün sürdü. Sadece bu sahne… Burada her bir veri arasındaki ilişkinin yani bağlantı türlerinin her birinin araştırmacılar için bir şekilde bir anlamı var.

Refik Anadol, Çatalhöyük Araştırma Projesi Arşivi, 2017
CR: 3 boyutlu bir küme analizi, ağ analizi gibi düşünebilir miyiz?
ŞÇ: Ve burada hala, başta gördüğümüz ilk sahnedeki veri kullanılıyor değil mi? Veri tabanının bütünü olduğunu söyleyebilir miyiz?
RA: Aynen. Veri tabanındaki imaj olarak kaydedilmiş tüm veriler var burada. Jpeg, tiff, giff, nef, raw uzantılı tüm dosyalar.
DT: İmajla kaydedilirken girilen tüm bilgiler mi peki? Yani veri tabanı üzerine giriş yapılan tanımlamalar, birim ve öğeler gibi bilgilerle ilişkisini de görüyor muyuz burada?
RA: Onlar da var. Tabii ne kadarına girildiğini ne kadar her birinin tutarlı bir şekilde içinde olduğunu göremiyoruz. Çünkü 500 bin tane nokta var; yani bir nevi araştırma ne kadar tutarlıysa o kadar tutarlı bir yapı, bir ağ ağacı çıkıyor.
ŞÇ: Bu sahnede de imge üzerinden ona bağlı olan bütün bilgiler burada görülüyor, değil mi?
RA: Evet, aynen öyle. Çünkü Dominik’in sağlayabildiği tek bir dosya vardı, yani big Picture CSV sadece imajlar için varmış diyebiliriz en azından.
CR: Bu hala imajlarla bağlantılı verileri mi ilişkilendiriyor, yoksa her şeyi mi?
RA: İmajlarla. Ama imajlarla ilgili her şeyi.
CR: Yani onlarla bağlantılı tüm meta verileri, ama aynı zamanda da bunun tüm görsel verilerini.
RA: Özetlemek gerekirse, bu, basitçe bu veri tabanında bulunan bütün imaj verileridir. Dominik, sanırım 400 megabayt ebadında bir dosya yollamıştı ve bunun içinde son 20 yılda herhangi birisi tarafından herhangi bir şekilde sınıflandırılmış her bir görüntü bulunmaktaydı. Bence buradaki uygun koşulları sağlayan ilk öğe 1996 yılına ait. Sütunlar halinde ve çok sayıda bilgi var.

Vorteks t-SNE: Doğrusal Olmayan Boyut İndirgeme, Refik Anadol, Çatalhöyük Araştırma Projesi Arşivi, 2017
RA: Bu sahne ise basitçe bu imajlar arasındaki 50 çapraşıklık bağlantısının bir sonucu olarak ortaya çıkan kümedir. Bu yüzden bu denemeyi yapmak oldukça eğlenceliydi. Yani ben birisi bu arşivin tamamını veri evrenine dağıtacak olsa ne olacağını görmek istedim. Bu bir hayli galaktik bir duygu. Yani bu aynı veri evrenine uygulanan bir vorteks (girdap) algoritması. Şu an bunlar sadece noktalar, bağlantılar değil. Daha önce gördüklerimiz bağlantılardı. Ama şu anda bunlar boşlukta yer alan tek tek öğeler. Bu epik bir deneyim. Bilginin yoğunluğu boşluğa yayılıyor…
CR: Arkeologlar açısından bunların hepsinin boşluğa dağıldığını deneyimlemek çok üzücü olmalı.

Refik Anadol, Çatalhöyük Araştırma Projesi Arşivi, 2017
RA: Ancak, bunun ardından gelen bir diğer sıçramalı kurgu da türbülansın uygulanmasıyla meydana geliyor. Bu da gördüğünüz tür bir bulgudur. Bu dondurulabilir. Bu bir 3-Boyutlu heykel olabilir, bir VRP (Sanal Gerçeklik Prototipi) vs. olabilir. Burada aynı bilgiyi daha şiirsel bir biçimde görüyorsunuz. Bir önceki koridorun ardından bu çok daha ruhani, göksel bir his yaratıyor.
CR: Bu çok organik. Denizanası gibi… Denizde yaşayan varlıklar gibi…
RA: Bu arada, tüm kurguyu düşündüğümüzde bu bir hayli çizgisel olmayan bir deneyim. İzleyen kişiler bunun herhangi bir bölümünün başlangıç olduğunu düşünebilir. Sonu da yok. Ancak bence bu veri setinin ne kadar muazzam büyüklükte olduğunu takdir edebilmek adına bu gibi bir sahneyi eklemek çok faydalı oldu. Ayrıca işittiğimiz ses de tamamıyla aynı veri setinden oluşturuldu. Folkwang Academy’den arkadaşım Kerim Karaoğlu ile geçtiğimiz altı yıl boyunca birlikte çalışıyoruz. Sese de bir belirsizlik yüklemek yerine bir uyum ya da sonik açıklama kazandırmak çok önemli. Demeye çalıştığım, mesela şiirsel diyebileceğimiz bir ses yapmak çok kolay, ancak bunu aynı veri setinden yapmak çok zor. Bunun adı “Pure Data (Pd)” (Saf Veri). Bu, o kalıpları bulmak için bu CSV dosyalarını kullanan bir yazılım. Kerim’le birlikte çok defa çalıştık. Her bir sahnenin ses tonu nedir? Kerim, Essen’deki Folkwang Üniversitesi’nden ve aldığı eğitim de ağırlıklı olarak müzikte elektronik kompozisyon konusuna dayanıyor. Bu yüzden sınırları hep zorlar kendisi ve üniversite bölümü olarak da bu alanda bir hayli benzersizdirler. Müzikal düşünce alanında bu akımı temsil ediyor.
ŞÇ: Peki, o da senin hazırladığın görsel deneyim için bir ses kurgulamakta arşivin tümünü mü kullandı?
RA: Evet. Yani, Dominik CSV dosyalarını paylaştı ve bizim temsillerini ürettiğimiz dosyalar tam anlamıyla müzik kompozisyonlarını meydana getirenlere karşılık geldi. Sesin ve görsellerin bu kadar iyi senkronize olmasının sebebi, gerçekten sesin de görseller işlenirken okunan aynı veriler ile üretilmesinden kaynaklanıyor. Gördüğümüz ve duyduğumuz makinenin çok paralel bir anı. Bu tamamıyla bir deneydi. Ama sonuçta çok esrarengiz bir durum ortaya çıktı, ancak bu tamamlayıcı bir deneyim de oldu.
RA: Yani aslında eğer vakit bulabilirsek, başka bir sergi kapsamında her bir eser tekil bir deneyim olabilir. Çünkü bunların her biri çok farklı deneyimler. Bu, bir sürü fikrin bir arada yoğrulmuş hali gibi. Bir anlamda, aynı evrenin farklı bakış açılarından görünümleri gibi. Makine zekâsının aynı mekânın görsel ve sessel ifadelerini ortaya koyması çok ilginç. İlginç bir şekilde, böyle olunca daha da somut bir hal alıyor. Bunu Sanal Gerçeklik’te görmek de insanın aklını başından alır diye düşünüyorum.
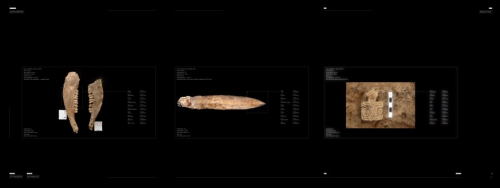
Obje Tanımlama: Buluntuların Özellik Sınıflandırması, Refik Anadol, Çatalhöyük Araştırma Projesi Arşivi, 2017
RA: Bu gördüğümüz bölüme de ben sergi bölümü diyorum. Biz bir model kurduk. Zamanımız da kaynağımız da sınırlıydı, bu nedenle her şeyi bir yere varacağı ümidiyle yapmamız gerekiyordu. Yapılacak ilk iş, bu girdilerin nasıl oluşturulacağı konusuydu. Kullanacağımız t-SNE algoritmasını zaten üretmiştik. Biz de doğrudan Dominik’in önceden tanımladığı kategorileri izledik. Ve bunları t-SNE grupları uyarınca gruplara ayırdık. Sonra da aynı girdiyi bir model olarak buluta besledik ve bu da bir hafta daha aldı.
CR: Buradaki kilit konu, girdinin de bağlantılandırıldığı bir başka meta veriye sahip olması gerekliliği, değil mi?
RA: Kesinlikle. Zaten bu da büyük oranda hazırdı. Tabii doğru olduklarını varsayarsak. Bundan sonra model de girdinin mutlak gerçeği haline geliyor. Elimizde bir tahmin modeli var. Ardından da aynı modelleri arşivin tamamına uyguladık. Buradaki sahne, sayıların gerçekte ne kadar akıl almaz düzeyde doğru olduğunu gösteriyor. Yani, 0.9, Yapay Zekâ kapsamında çok başarılı bir sayıdır. Neredeyse insan algılaması ve görmesinden daha hızlı. Üzücü ama gerçek, kusura bakmayın. Bence diğer iyi şeyler arasında bu bulguların makinenin bile birçok tahminde bulunabileceği kadar benzersiz olması var. Burada 0.85 düzeyinde güvenilirlik seviyesine çektik, çünkü bu bile insan görmesinden daha yüksek. Bunlar da Yapay Zekâ’nın ürettiği sahneler. Nasıl oldu da çalıştı? Yani, geleceği düşünecek olursak, daha sizler sahada araştırmanızı yürütürken bunları tanımlayan bir uygulama olabilir. Bir hayli sanatsal bir bakış açısından, yani hiç bilgisayar bilimi uzmanı olarak değil, çok alçak gönüllü kişisel bir yolculuğa çıktık, ama eminim kimilerinin karmaşık çalışan bilgisayar bilimi odaklı zihinlerinin elinde bu son derece kolay olacaktır. Bu sadece bağlama odaklanarak bolca zaman ve özveri gerektiriyor. Bu anları tespit eden ve tanımlayan bir makine görüyoruz ve güvenilirlik düzeyleri çok yüksek. Bence inanılmaz fırsatlar sunabilir.
Bu 10 senaryonun hepsine birden baktığımızda, her bir sahne benim açımdan da heyecan verici bir deney oldu. Doğrusal bakıldığında sıkıcı olabilecek bir deneyimi ayrıştırıp analiz ederek, belki bir hikayenin bölümleri gibi her birini farklı şekillerde ele alacak olsak nasıl olur? Burada açık kaynaklı kodu kullanıyor olmamızın da çok önemli olduğunu söylemeliyim. Her şey açık kaynak.
DT: Ayrıca bu iş Çatalhöyük Araştırma Projesi’nin bütün fikirleriyle de örtüşüyor.
ŞÇ: Ian Hodder’ın “Dolanıklık” (Entanglement) teorisinin vücut bulması gibi bir şey. Bu teoriyi anlattığı kitap, Entangled: An Archaeology of the Relationships between Humans and Things’in kapağında da 3. Sahne’deki gibi bir ağ kullanmış.
DT: Bütün bu konuşmada bahsettiğimiz temel bileşen (principle component), ağ analizi (network analysis) vs. aslında işin bilgi üretimi boyutunda da yapılıyor. İşin arkeolojik araştırma boyutunun bir parçası bunlar. Bunu sanatsal bir yaklaşımla yeniden dönüştürebilmek çok ilginç. Ben de Çatalhöyük’te 13 yıldır çalıştığım için o verilerin girişini yapanlardan biriyim. O karmaşık ağın bir parçasıyım. Ama bu şekilde karşımda gördüğümde büyüleyici buluyorum. Zaten yola çıkış sorumuz, “elimizde Çatalhöyük’e ait acayip büyüklükte bir veritabanı var, bunu sergide nasıl gösteririz?” idi. Dolanıklık (Entanglement) teorisini nasıl katabiliriz bu anlatıma? Öyle bir toplu ifade biçimi oldu ki bu eser, biz çok etkilendik ilk sonuçları gördüğümüzde.
RA: Veri muazzam, güzel bir zaman harcanmış. Çok şeyler yapılmaya müsait.
DT: Evet, veritabanı en başından beri kurgulanırken deneysel uygulamalara açık olsun diye oluşturulmuştu. Sadece arkeolojik araştırmanın ihtiyaçlarına cevap vermesi için değil disiplinler arası çalışmalara kaynak olsun diye kurgulanıyordu.
RA: Genel anlamda hem arkeoloji hem de antropoloji bağlamında ve bir makinenin kavrayışına zemin olacak büyük bir veritabanına sahip olunduğunda, makineler bu ölçekte iş birliği yapacağımız ortaklarımız olabilir. İnsanların bu çalışmayı, bu sergiyi bundan 50 yıl sonra gördüğünü bir hayal edin. Bu biraz acayip olacaktır. Ya da aradan iki veya üç asır geçtikten sonra nasıl olur? Eğer makine zekâsını bugün uygulamaya koyarsak, bu toplum açısından çok daha büyük gelişmeleri imkanlı kılabilir.
CR: Bu çalışma, ağların polimetrik bir biçimde gösterilmesi. Ve sanatsal deneyimleriniz ve bilgilerinizden faydalanarak, aynı veritabanına yöneltilen bir araştırma sorusu üzerinden bir sinerji belki tekrar uygulansa harika bir şey olurdu. Örneğin, bir bölüme daha yakından bakarak bunun aslında ne demek olduğuna bir göz atılsa… Bu, arkeolojik verilerin değerlendirilmesi açısından muhteşem bir fırsat olurdu.
* Medya enstalasyonu hakkında ayrıntılı bilgi için tıklayınız.