
Refik Anadol “Bir Kazı Hikâyesi: Çatalhöyük” sergisi kapsamında Çatalhöyük Araştırma Projesi Arşivi’nden hazırladığı medya enstalasyonunu anlatıyor.
Bu proje Çatalhöyük sergisi için kullanılan, hemen hemen 25 yıla tekabül eden dijital verinin yapay zekâ algoritmalarıyla tekrar analiz edilmesiyle hazırlandı.
Proje sırasında elimizdeki yaklaşık yarım milyonluk, genellikle imge ağırlıklı veri yığınını açık kaynaklı kodla beraber tekrar analiz etmeye çalıştık.
Tahmin edersiniz ki, 25 yıla yakın bu kadar kapsamlı bir veriyi bir seferde büyük ölçekte görebilmek hemen hemen mümkün değil. Bunu anlayabilmekte başımıza gelen en büyük sıkıntı, bir yandan birçok kişinin bu verilerle uğraşmış olmasıydı. “Peki bu kadar karmaşık bir ağı acaba çok basit bir şekilde algılayabilir miyiz ve bunu algılayabilirsek bundan bir ‘heykel’ ve şiirsel bir yaklaşım çıkartabilir miyiz?” diye düşünmeye başladık.
Sonuçta makine zekâsı bizlere bu imgelerin kendi arasındaki karmaşık ilişkisini basit bir şekilde bir heykel olarak sunabiliyor. Kazının geçtiği yer olan, mekân da aslında verinin bir parçası.

Burada gördüğümüz imge, aslında bir veridir. “Çatalhöyük 3D Digging Project” ekibi uzunca bir süre “drone”larla kazının yapıldığı mekânı defalarca fotoğraflayarak üç boyutlu bir haritasını çıkarıyor. Benim de aklıma bir makine zekâsı bu mekânı görmek isteseydi nasıl görürdü gibi bir soru geldi. Bir imge olarak tahminen klasik bir fotoğraf, ya da klasik bir 3D modelden öte belki de bu iki düzlemin çakıştığı daha resimsel, pastel renklerde bir gerçeklik gibi düşünmeye başladık.

Ardından bu sahnede gördüğümüz her küre 25 yılda konuşulmuş her bir veriye tekabül ediyor. Arşivde bulunan tüm veriler aslında o kadar büyük ve geniş ki, binlerce metrekarelik bir alanı ve belki daha da fazlasını kaplayabildiğini de gösteriyor. “Veri nedir, fiziksel olarak bir karşılığı var mıdır, 25 yıldır konuşulan ve düşünülen şeyler aslında ne kadar yer kaplayabilir, bunların eğer çıktılarını alsaydık kaç sayfalık bir kitaptan konuşuyorduk?” gibi soruları sorduğumuz zaman aslında bu da onun fiziksel ölçekteki karşılığı gibi düşünebiliriz.
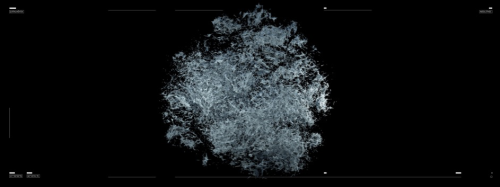
Burada gördüğümüz sahne ise aynı veri noktalarının bir kümesel heykele dönüşmesi. Veri noktaları bir heykele dönüşüyor ve bu heykel bizlere veri tabanının farklı açılardan aslında ne kadar karmaşık bir formda olduğunu gösteriyor. Her bir veri noktası ve kendi aralarındaki ilişkiler benzerlik ve dokümantasyon yapan kişilerin tanımladığı özelliklere göre kuruluyor.

Bir yandan da bu sonsuzluk etkisi içerisinde işi izliyor olmak daha izleyiciyi içine alan bir deneyim yaratıyor. Hem de bunu yaparken bu iki boyutlu ve yassı düzlemdense biraz daha derinlik kazanabildiğini düşünüyorduk. Mesela biraz önce gördüğümüz heykelin sadece noktaların ve tüm arşivdeki verilerin gösterdiği bir alan gibi düşünebiliriz. Burada aslında bir şiirsellik yakalanabilir mi diye düşüyordum bütün bu veriyi bir anda boşluğa yaysak, fırlatsak ve acaba sıfırdan başlama anını tekrar toplamaya çalışsaydık veri tabanını yenileyebilir miyiz gibi düşünebiliriz.

Burada kronolojik olarak soldan sağa doğru da arşivdeki tüm imgelerin dizilimini görüyoruz. Sadece bu sahnenin oluşması 3 gün sürdü, böyle basit gibi konuşuyor olabilirim ama 10 deneme hazırladık ve gördüğümüz her sahne ve her deneme, günlerce süren hesaplamaların çıktılarıdır.

Bu görüntüde ise gördüğümüz her bir küp veri havuzundaki bir noktaya işaret ediyor ve her çizgisel deneyimde bir araştırmacı tarafından o veriye verilen ismi temsil ediyor. Kaç kişi çalıştı 25 yılda bilmiyorum, ama yüzlerce insanın emeğinin bir şekilde değdiği bir dosyadan bahsediyoruz.
Aslında iş kendi içinde her bir kesitin başlı başına ayrı bir iş olma potansiyelini taşıdığını söyleyebiliriz. Sonra tekrar iş başa dönüyor ve en baştaki obje tanımlama algoritmasına başlıyoruz. Bu arada buradaki rakamlar çok enteresan, gördüğümüz herhangi bir obje için belli konseptler yapmamız gerekiyor, yapay zekânın modele ihtiyacı var ve model yapmamız gerekiyor. Elimizdeki model araştırmanın kendisi, zaten ciddi anlamda araştırma yapılmış. Buradaki buluntunun neye tekabül ettiği zaten İngilizce olarak tanımlı bir halde arşivde duruyor. Yapay zekâ sadece bunun ne olduğunu, yani 1 mutlak gerçekse, makine için 0’ın, 1 ve 0 gerçekliğinde yanlış olduğunu düşünüyoruz. Burada obje tanımlama bölümünde gördüğümüz işlem yaklaşık 250 bin kere ve yaklaşık 3 dakika içerisinde makine zekâsı tarafından uygulandı. Gördüğünüz sahnede bunu aşırı yavaşlatıyoruz ki bu düşünme biçimini insan olarak algılayabilelim.
Şu anda gördüğümüz bütün imgeler, “object detection” yani obje tanımlama algoritmalarının kullanılması sırasında ortaya çıkan belli birtakım kelimelerin aslında bir insandan çok daha hızlı ve daha iyi bir şekilde bir objeyi tanımlayabildiğini fark ediyoruz.
0.87 bir insandan çok daha başarılı, çok daha hızlı ve doğru bir tanımlama olarak geçiyor bilgisayar bilimlerinde. Buradaki hiçbir tanımlama 0.85’in altında değil. Şimdi bu kadar kuvvetli bir güç ve düşünme şekli varsa acaba 25 yıllık bütün bu deneyimi bir kere daha sorguladığımız zaman, bir sonraki 25 yılı nasıl hayal edebiliriz? Kuvvetle muhtemel ne kadar hızlı düşünebileceğimizi, iyimser olursak büyük bir ihtimalle nasıl ağlar kurabileceğimizi düşünebiliriz. Yapay zekânın sadece kötümser bir güç değil iyimser olarak bizleri parlak bir dünyaya taşıyabileceğini kanıtladığını düşünüyorum. Sadece bu rakamlarla bile bunu görebiliyoruz.
Mesela bu kadar karmaşık bir veri tabanını çalışanlar dışında biz nasıl görebilirdik gibi düşünmeye başladığınız zaman, aslında makine zekâsının büyük bir avantaj olduğunu görmeye başlıyoruz. Aradaki daha minik ve karmaşık yapıların, makro ve mikro düzeyde aslında muazzam ipuçları verdiğini tahmin ediyorum araştırmacılar için. Yani şu an sadece bir sayısal, soyut ve sanal bir yaklaşım fakat daha yakın bir gelecekte araştırmacılar bu kadar kompleks ve büyük bir veriyi kendilerine avantaj hale getirebilirler.
Bunun yanı sıra, duyduğumuz müzik de sadece klasik bir harmoni ya da ses tasarımı değil. Folkwang Academy’de doktorasını yapan müzisyen ve aynı zamanda ses tasarımcı arkadaşım Kerim Karaoğlu da aynı verileri ‘Pure Data’ isimli bir programa okutarak bir kompozisyon ortaya çıkardı. Duyduğumuz ses sadece epik bir etki ya da sinematografik bir etki yaratmaktan öte o an gördüğümüz veri yığınının müziksel karşılığını da araştırmaya çalışıyor. Tabii ki duyduğumuz sesler çok deneysel bir seviyede. Kimi zaman harmoni yaratabiliyor kimi zaman yaratamıyor.
Dolayısıyla belki çok mikro ölçekte, yapay zekânın iki düzlem arasındaki karar verme anının en yavaşlattırılmış heykel anını görüyoruz. Bir şekilde aynı heykele odak uzaklığı eklediğimiz zaman belki de aslında yeni bir sinema dili ortaya çıkarma ihtimali olabilir, yeni bir fotoğraf dili konuşuyor olabiliriz. “Neuro photography” gibi bir terim kullanabiliriz.
Bu projede kullanılan her kod, açık kaynaklı ve herkesin erişebileceği yazılımlar. Bunun çok değerli ve umut verici olduğunu düşünüyorum.