
Refik Anadol explains his media installation developed from the Çatalhöyük Research Project Archive as part of ANAMED’s “The Curious Case of Çatalhöyük” exhibition.
This project involves the use of machine learning algorithms that re-evaluate of all Çatalhöyük’s data corresponding roughly to a 25-year time frame.
Relying on open source codes, we attempted to re-assess about half a million pieces of available data, most of which were images.
Covering nearly 25 years, such a broad and comprehensive amount of data is seemingly impossible to perceive at once. One of the biggest difficulties that we faced, while trying to comprehend it, was the fact that a lot of people have worked on this data. We eventually started to question if a network of such complexity could be perceived in a more accessible fashion. If this was indeed possible, we wanted to know if a “sculpture” and a poetic approach could be extracted from it.
Indeed, machine intelligence can present the complex relationship between these images in a simple fashion such as in the form of a sculpture. The space, which is where the excavations took place, is also a part of the data.

The image we see, now, is actually a datum. “Çatalhöyük 3D Digging Project” team took photographs of the excavation site with drones over a long period and built a three-dimensional map of the space. And, I asked myself, “What would it look like if machine intelligence were to see this space?” We started to think about this not like the image of a classic photograph or a classic 3D model, but as something more. Perhaps it would result as a reality where these two planes coincide in a more pictorial way, with pastel colours. Actually, that’s why we started this work in such a way.

Here, each of the spheres that we see corresponds to all the data that has been talked about in these 25 years. The data available in the archive is so immense that it could fill thousands or more of meters squared. This project reveals itself as a translation into the physical plane, by questioning the nature of data; whether it could have a physical counterpart; about how much space 25 years of discussions and thought would occupy; and about how many pages it would include if printed as a book.
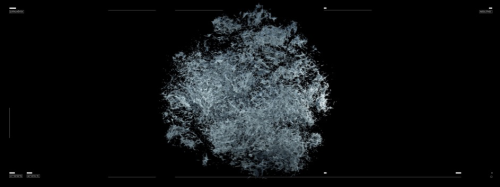
What we are seeing now is the sequence of these same data points being transformed into clusters, and later on, these data points are transformed into a sculpture, and eventually this sculpture starts to reveal to us how complicated it actually is as a (physical) form, from various different aspects. Each data point and their relationships with each other are established through a correlation based on similarity and on characteristics defined by the people implementing the documentation.

On the other hand, viewing the work through this infinite effect creates a more ‘immersive’ experience. We also thought that in doing this, it could gain a little more depth instead of this two-dimensional and flat plane. For example, we can consider the sculpture we just saw as a field revealed only by the points and the data in the entire archive. I keep thinking whether it is possible to catch a glimpse of poetry here; if we were to disperse all this data into the empty space, to launch it into the void, and attempted to recapture the moment of its inception, would it be possible to renew it, as it were?

In this scene, we see the entire sequence of the image archive, arranged chronologically from left to right. Just the making of this scene took 3 days. It might appear to be a simple task but we prepared 10 scenarios; every scene and trial we see, here, is the output of calculations that last for days.

Each cube indicates a point in the data pool and each linear experience represents the name assigned to that data by a researcher. I do not know how many people have worked on it in 25 years, but we are talking about a file that hundreds of people have toiled over in some way.
Actually, I think we could say that each individual section of the work has the potential to become a work in its own right. Then, once more, the work starts again, and it goes through the initial phase of the algorithm of object detection. By the way, the figures here are quite interesting, for any object that we see now we have to prepare certain concepts, artificial intelligence requires a model, and we have to come up with a model. What we have here is actually a research on models – and there has been a serious amount of research already conducted. What a find at hand corresponds to is already included in the archive, described in English. Artificial intelligence only has to determine what it is. That is, if 1 corresponds to absolute truth, then in the reality of 1 and 0 for the machine, 0 would be false. The operation that we see here was implemented by machine intelligence, approximately 250 thousand times over, and in about 3 minutes. We are currently slowing it down extremely so that humans can witness such kinds of information processing.
All of the images that we see now act as evidence of certain sets of words, which emerge during the use of “object detection.” That is, algorithms that define objects do so with greater speed and accuracy than any human being.
Confidence level 0.87 is a lot more successful than a human being, it is a much faster strength of a correct definition in terms of computer science. None of the definitions here are below 0.85. Now, considering that we have such a powerful force and means of processing information, when we run 25 years of experience and data through our examination once again, or if we contemplate and imaging the next 25 years, then we can consider how much faster we would be able to think, and optimistically, what sorts of networks we could establish. I think this would prove that artificial intelligence is not a negative power, but a promising possibility that could convey us into a brighter world. These figures, on their own, are enough evidence to prove it to us.
For instance, as we consider how such a complex entity would be seen by outsiders to the project, we see that machine intelligence is, in fact, a major advantage. I would guess that the smaller and more complex structures in between provide colossal clues to researchers at the macro and micro levels. In other words, at present this is only a digital, abstract, and virtual approach. Yet, in the future, researchers can use such complex and vast data collections to their great advantage.
Also, the music we hear is not just a classy harmony or sound design. My friend Kerim Karaoğlu, a musician and sound designer pursuing his PhD research at Folkwang Academy, used the same data and put it through a program called ‘Pure Data’ to come up with this composition. The sound that we hear is not there to create an epic or a cinematographic effect. Rather, it aims to explore the musical counterpart of the accumulated data that we are viewing at that moment. Of course, the sounds we hear are on a rather experimental level. Sometimes there is a harmony playing, and sometimes there is not.
Therefore, perhaps on a micro scale, we can see a slowed down and sculptural moment of the instant decision making of artificial intelligence between the two planes. Perhaps if we add a focal length to the same sculpture, this might lead to the creation of a new cinematic language, a new photographical language. We can address this as ‘neuro photography.’
The codes used in this project are open source. Meaning, these are things that anyone can download and use from the Internet. I think this is quite significant and it inspires hope.